上次说到在Bluemix新建一个简单的Java webapp,现在这个Java应用需要访问数据库服务来存取数据,我们来看看在Bluemix上该如何使用和管理数据库服务。首先,Bluemix上有多种数据库服务供选择,有传统的关系型数据库也有NoSQL (包含了IBM收购的Cloudant),因为Connections本身支持包括DB2, Oracle和SQL Server,所以我们选择基于IBM DB2的数据服务。
可以从Dashboard的Service tab或者直接从Catalog进入服务选择界面,选择Data Management -> SQL Database:

创建时需要指定服务名(注意这个名字既不是数据库名也不是schema名,仅仅是个标示符),同时如果应用已经创建好,可以在创建数据库服务的时候直接绑定应用。
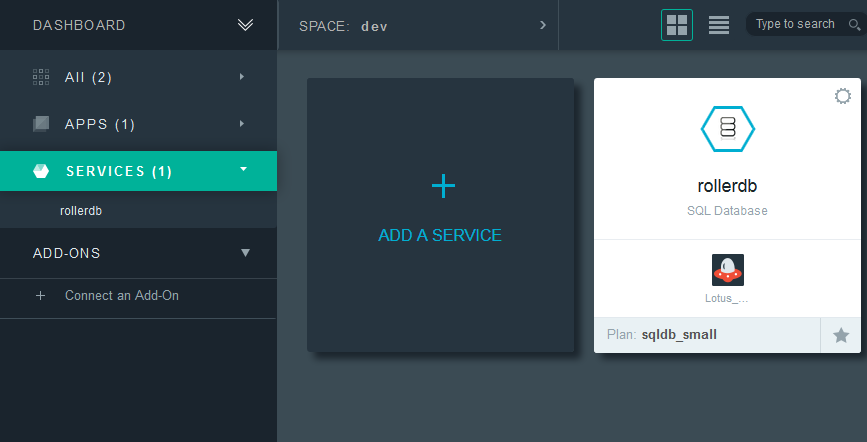
创建好数据库服务后回到Dashboard,可以看到名下有一个应用和一个服务 – APPS(1) & SERVICES(1) – 移植Connections Blogs需要的全部组件都齐了。
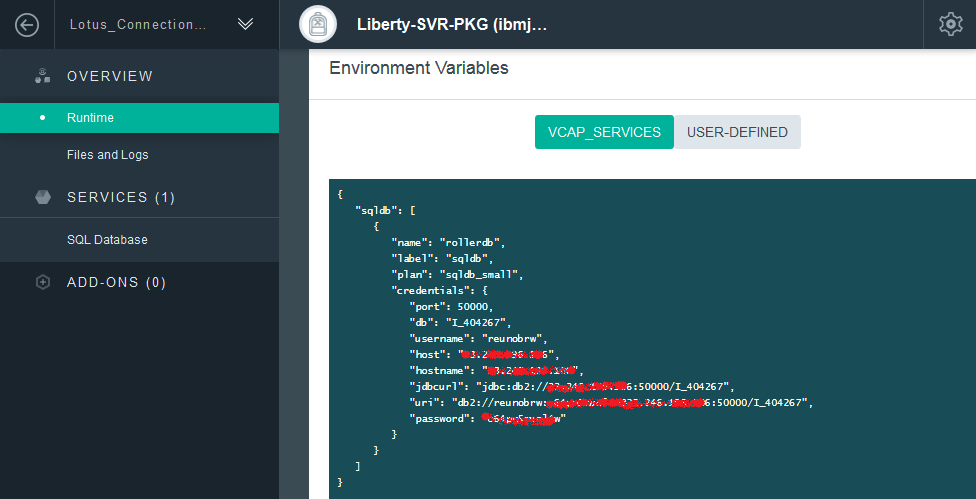
在创建并绑定数据库服务后,点击应用的Runtime选项,可以看到新生成的环境变量。这里包含了有关数据库连接的全部信息 – 注意所有的配置信息都无法更改,一旦重新创建数据库服务,数据库名、用户名、密码等都会随之改变。这些所谓’环境变量‘实际上是保存在Liberty的server.xml中,这样app在启动的时候可以正确的找到JNDI data source。
接下来,我们需要创建数据库schema,tables,indexes…点击进入添加好的数据库服务,点’Launch’按钮会打开一个数据库管理界面,点击‘Work with Database Objects’就可以开始创建数据对象了。Bluemix的数据库服务不支持用本地的数据库客户端直接连接,所有的数据管理操作都必须在Web界面上完成。
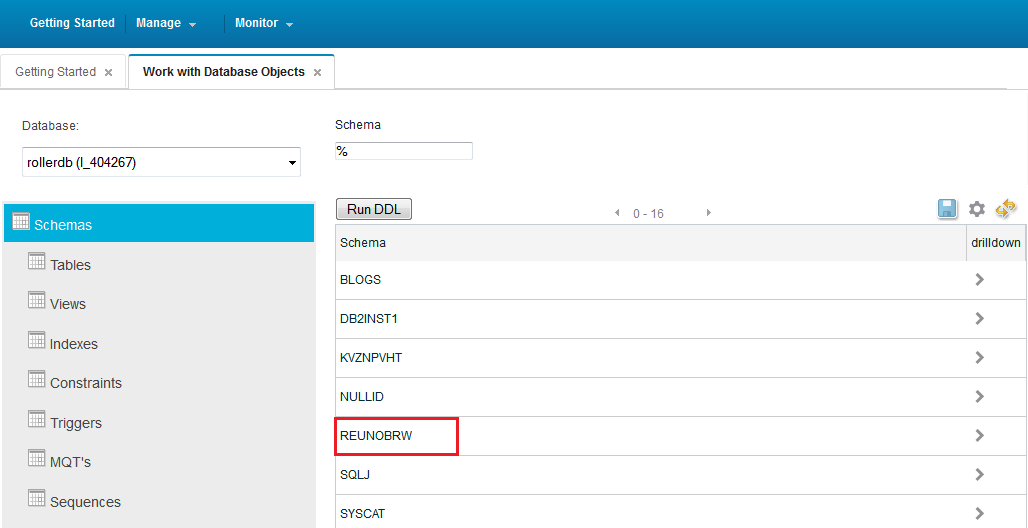
大家注意到上图有个名叫‘REUNOBRW’的schema,它和上上图里的环境变量中的数据库用户名是一致的。之所以要手工创建‘REUNOBRW’ schema的原因在于我们要移植的Blogs早期版本(1.0.2)里,所有的数据库访问代码是仅有table名,不带schema名的,如下:
<select id=”getWebsiteById” parameterClass=”string” resultMap=”Website” >
SELECT * FROM website WHERE id = #value#
</select>
在Bluemix环境中,这样的调用会自动在前面以用户名作为schema名。除非我们修改全部的SQL把它们都带上schema名,否则只能创建一个和用户名同名的schema。这个做法虽然可以工作,但一旦数据库服务重建schema也必须要重建,作为测试可以但作为生产环境的开发这样是不可取的。创建好schema后,可以创建table等对象了,点击Run DDL来指行数据库命令(注意不是所有的SQL都支持,比如我们无法创建table space)。下面是在创建好tables、运行应用后查询用户表的例子 –
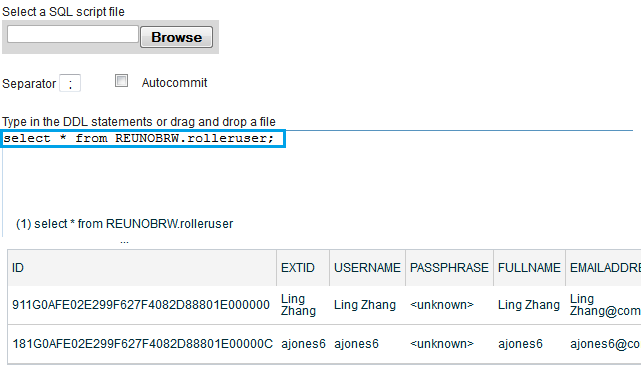 现在可以把Connections Blogs build成一个.war文件,通过cf push到Bluemix上,它可以正确的连接数据库,但界面上有很多错误,绝大部分是因为已有代码是在WebSphere Application Server下测试运行的,在Liberty环境下存在问题。另外也没有办法登录,因为我们还没有定义用户库。下篇文章我们将继续讨论应用的迁移。
现在可以把Connections Blogs build成一个.war文件,通过cf push到Bluemix上,它可以正确的连接数据库,但界面上有很多错误,绝大部分是因为已有代码是在WebSphere Application Server下测试运行的,在Liberty环境下存在问题。另外也没有办法登录,因为我们还没有定义用户库。下篇文章我们将继续讨论应用的迁移。
2 replies on “上手Bluemix (2)”
请问dbname, scheme name, table name都是可以自定义的对吗?
schema和table都可以自定义,dbname不可以。